Publications
2026
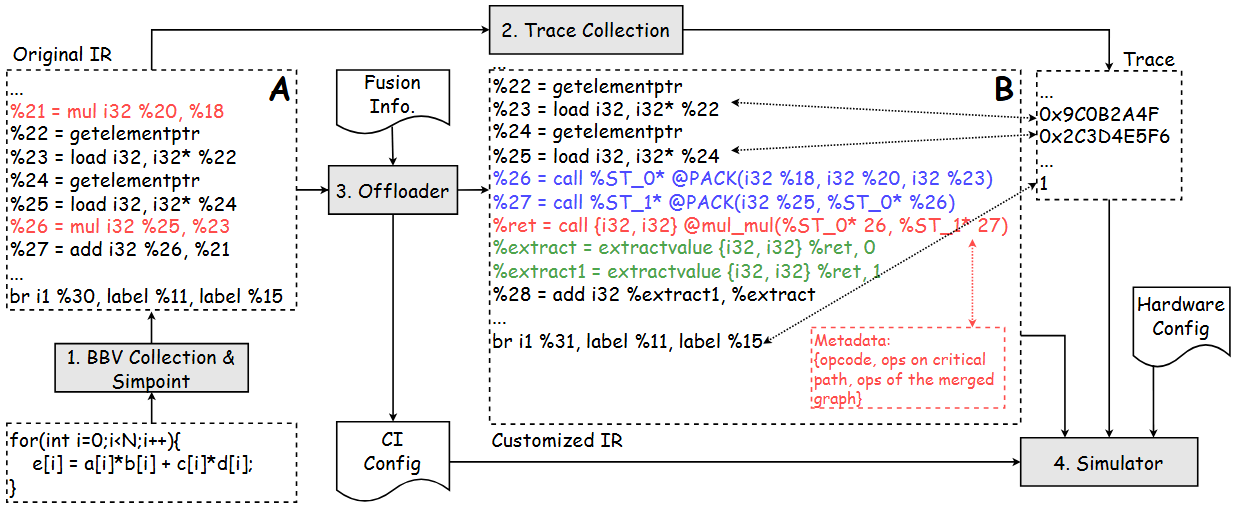
- CISim: ISA-Agnostic Custom Instruction Simulation for General-Purpose ProcessorXiaoyu Hao, Sen Zhang, Liang Qiao, Jun Shi, Junshi Chen, and Hong AnIn 2026 Design, Automation & Test in Europe Conference & Exhibition (DATE), 2026
2025
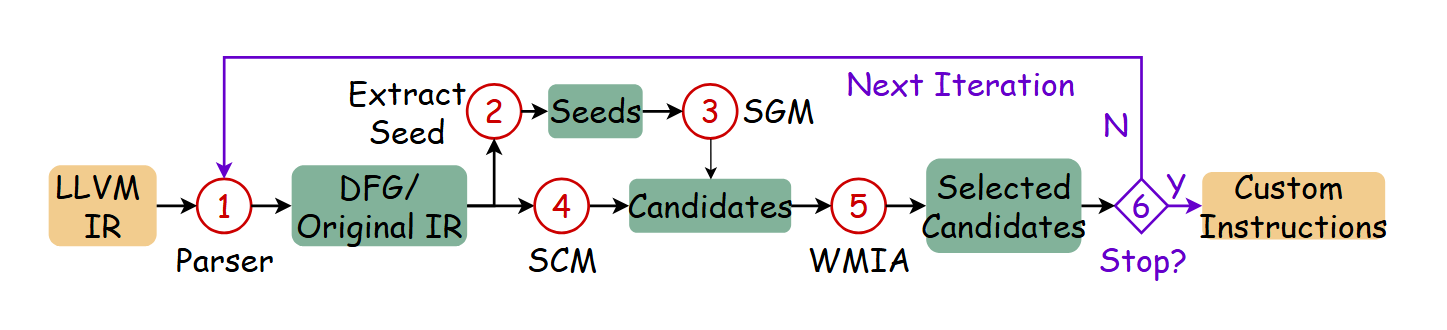
- CIExplorer: Microarchitecture-Aware Exploration for Tightly Integrated Custom InstructionXiaoyu Hao, Sen Zhang, Liang Qiao, Qingcai Jiang, Jun Shi, Junshi Chen, Hong An, Xulong Tang, Hao Shu, and Honghui YuanIn Proceedings of the 39th ACM International Conference on Supercomputing, Salt Lake City, U.S.A., 2025
Extending existing architectures with customized instruction extensions is emerging to achieve high performance and energy efficiency for specific applications. Automated discovery of custom instructions (CIs) is well-studied nowadays, which requires exploring combinations of different types and quantities of operations, resulting in a vast search space. However, previous works typically use microarchitecture-agnostic cost models, leading to suboptimal CIs that may degrade performance. They leverage graph isomorphism to reduce area overhead, but few of them consider its potential to benefit performance-oriented exploration. To this end, we present CIExplorer, a framework for adaptive CI exploration. We propose a Seed Growth Method (SGM) based on a genetic algorithm to discover CIs with the consideration of graph similarity. We also propose a compiler-assisted modeling strategy that applies a microarchitecture-aware cost model to estimate the potential benefits of CIs in exploration. We evaluate our framework using various benchmarks in SPEC2006 and Mediabench on in-order, 2-wide OOO, and 4-wide OOO processors. Experimental results demonstrate that CIExplorer achieves average performance improvements of 1.09 × and 1.13 × and energy improvements of 1.07 × and 1.10 × compared with Novia and MaxClique.
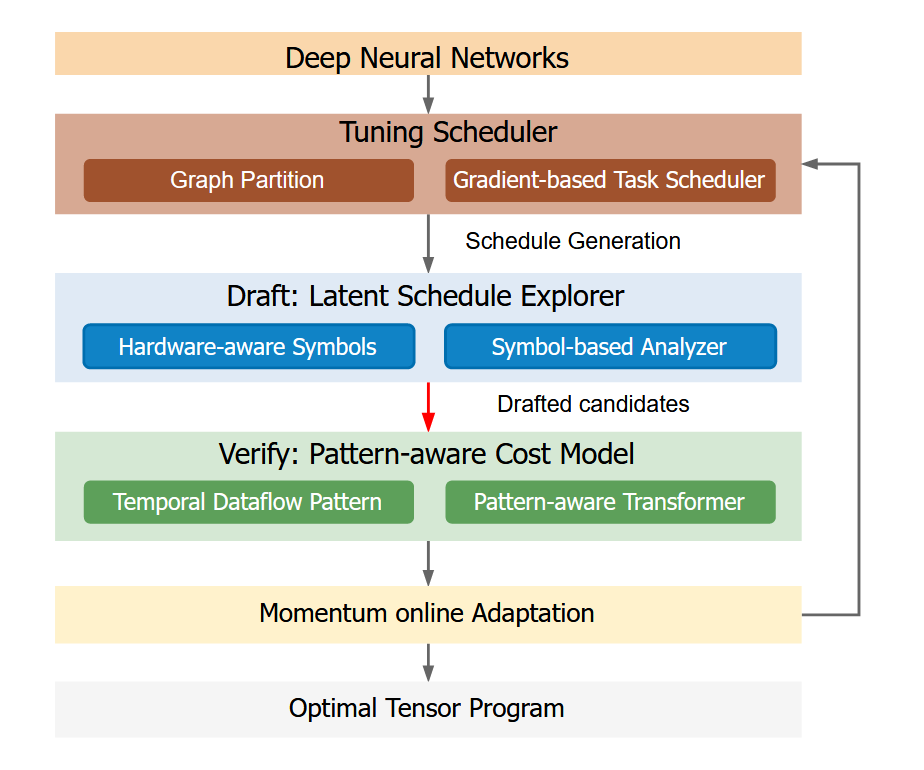
@inproceedings{hao2025ciexplorer, author = {Hao, Xiaoyu and Zhang, Sen and Qiao, Liang and Jiang, Qingcai and Shi, Jun and Chen, Junshi and An, Hong and Tang, Xulong and Shu, Hao and Yuan, Honghui}, title = {CIExplorer: Microarchitecture-Aware Exploration for Tightly Integrated Custom Instruction}, year = {2025}, isbn = {9798400715372}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3721145.3730421}, doi = {10.1145/3721145.3730421}, booktitle = {Proceedings of the 39th ACM International Conference on Supercomputing}, pages = {975-990}, numpages = {16}, location = {Salt Lake City, U.S.A.}, series = {ICS '25} } - Pruner: A Draft-then-Verify Exploration Mechanism to Accelerate Tensor Program TuningLiang Qiao, Jun Shi, Xiaoyu Hao, Xi Fang, Sen Zhang, Minfan Zhao, Ziqi Zhu, Junshi Chen, Hong An, Xulong Tang, Bing Li, Honghui Yuan, and Xinyang WangIn Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, Rotterdam, Netherlands, 2025
Tensor program tuning is essential for the efficient deployment of deep neural networks. Search-based approaches have demonstrated scalability and effectiveness in automatically finding high-performance programs for specific hardware. However, the search process is often inefficient, taking hours or even days to discover optimal programs due to the exploration mechanisms guided by an accurate but slow-learned cost model. Meanwhile, the learned cost model trained on one platform cannot seamlessly adapt online to another, which we call cross-platform online unawareness.
In this work, we propose Pruner and MoA-Pruner. Pruner is a ”Draft-then-Verify” exploration mechanism that accelerates the schedule search process. Instead of applying the complex learned cost model to all explored candidates, Pruner drafts small-scale potential candidates by introducing a naive Symbol-based Analyzer (draft model), then identifies the best candidates by the learned cost model. MoA-Pruner introduces a Momentum online Adaptation strategy to address the cross-platform online unawareness.
We incorporate Pruner into the TVM and conduct extensive experiments on three GPU-based platforms. Results show considerable speedup in schedule search time. In online tuning scenarios, Pruner and MoA-Pruner achieve an average speedup of 2.6 × and 4.82 × compared to Ansor. In offline tuning scenarios, Pruner achieves an average speedup of 4.75 × and 4.05 × compared to TenSet and TLP, respectively. Furthermore, Pruner achieves an average speedup of 4.08 × compared to MetaSchedule on TensorCore.@inproceedings{qiao2025pruner, author = {Qiao, Liang and Shi, Jun and Hao, Xiaoyu and Fang, Xi and Zhang, Sen and Zhao, Minfan and Zhu, Ziqi and Chen, Junshi and An, Hong and Tang, Xulong and Li, Bing and Yuan, Honghui and Wang, Xinyang}, title = {Pruner: A Draft-then-Verify Exploration Mechanism to Accelerate Tensor Program Tuning}, year = {2025}, isbn = {9798400710797}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3676641.3716269}, doi = {10.1145/3676641.3716269}, booktitle = {Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2}, pages = {949-965}, numpages = {17}, keywords = {code generation, compiler optimization, tensor program tuning}, location = {Rotterdam, Netherlands}, series = {ASPLOS'25} }